Object detection
Object detection goes a step beyond classification: it finds where objects are in an image and draws a labelled box around each one. In African contexts it powers tasks like counting livestock from drone imagery, spotting infrastructure in satellite photos, or locating individual plants in a field.
What the data looks like
A detection dataset is images annotated with bounding boxes, each box marking the location and class of one object. The annotation is far more laborious than classification, since every object in every image must be boxed, which makes tool choice and clear guidelines matter more. African detection data is dominated by aerial and satellite imagery for agriculture and the environment, where boxes mark fields, buildings, or vehicles, and by wildlife and livestock monitoring. As with classification, images captured in real African conditions, low resolution, oblique angles, dense scenes, are essential, because models trained on clean benchmarks degrade on them.
The most widely supported format is COCO, where one JSON file holds the images, the boxes, and the categories, linked by id. Each box is [x, y, width, height] in pixels from the top-left corner:
{
"images": [
{"id": 1, "file_name": "field_0007.jpg", "width": 1280, "height": 720}
],
"annotations": [
{"id": 1, "image_id": 1, "category_id": 1, "bbox": [340, 120, 85, 110], "area": 9350, "iscrowd": 0}
],
"categories": [
{"id": 1, "name": "cattle"}
]
}
COCO is worth using even for a small African dataset, because the evaluation tools below read it directly, so you avoid writing a custom parser and your results stay comparable with everyone else reporting mAP.
Annotation and evaluation
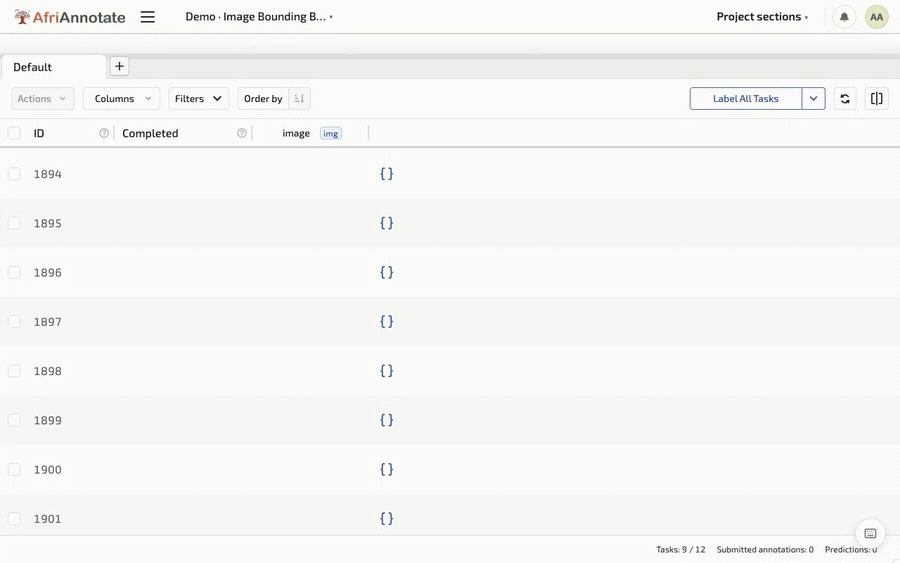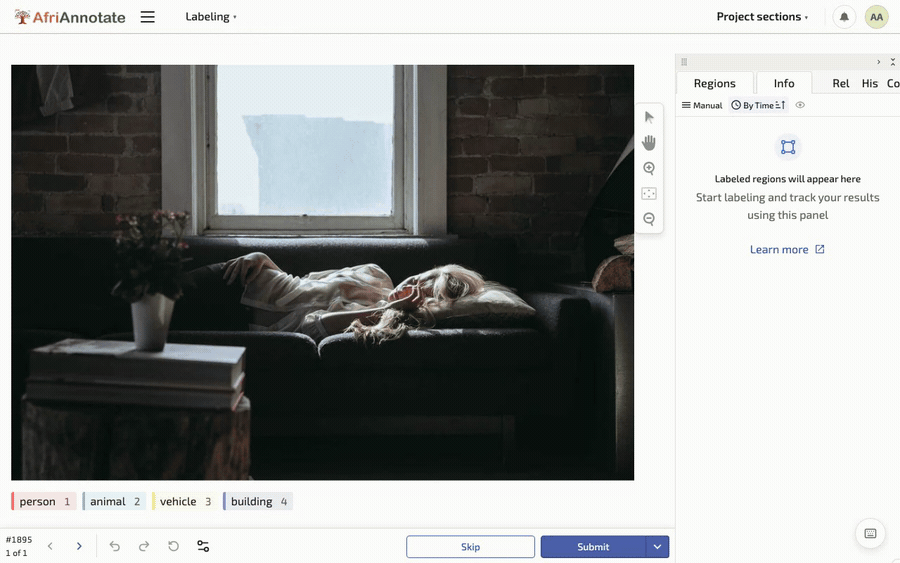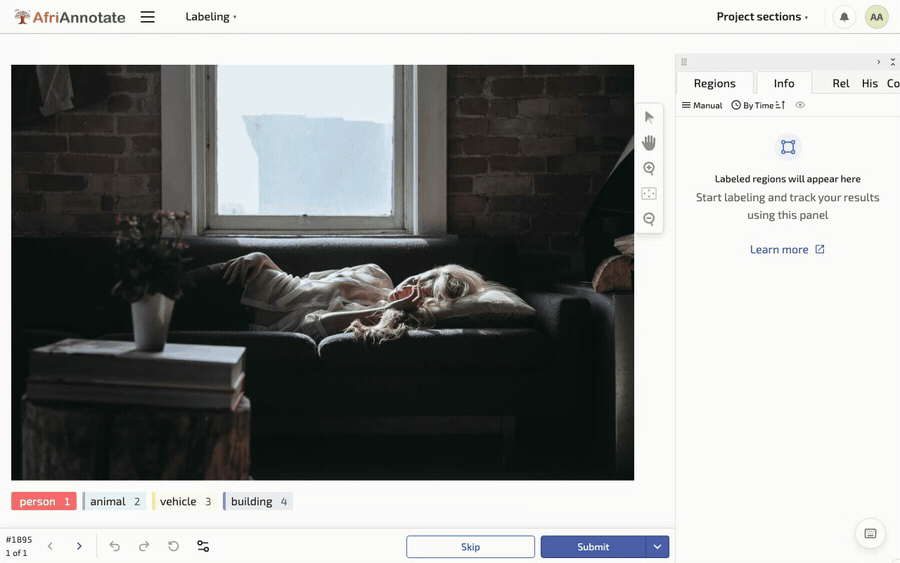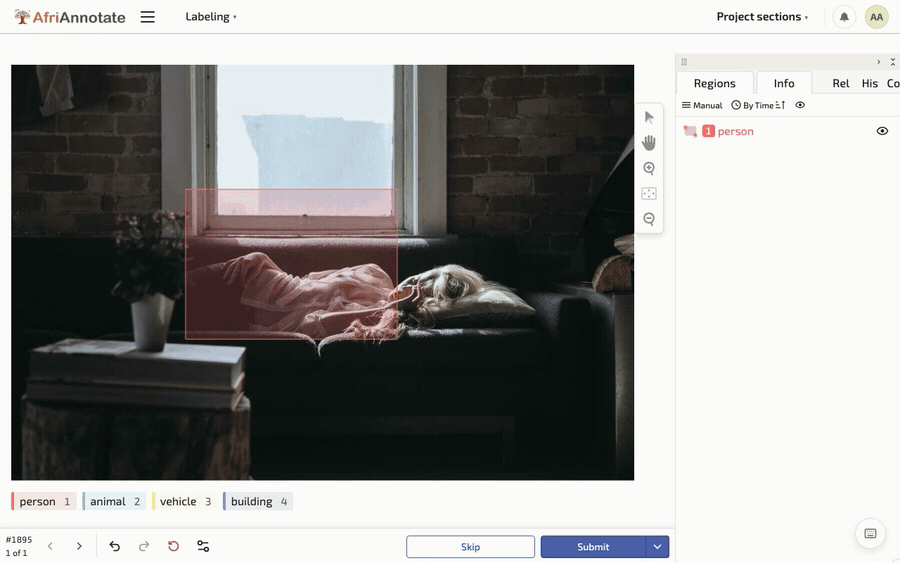
Box annotation needs explicit rules: how tightly to fit the box, how to handle occluded or overlapping objects, how small an object must be to mark, and what to do at the image edge. These rules are where annotators silently diverge, so pin them down and measure agreement on a shared set. Detection is evaluated with mean Average Precision (mAP), which rewards both correct labels and accurate placement, built on Intersection over Union (IoU), the overlap between a predicted box and the true one. Report the IoU threshold you used, since mAP at a loose threshold flatters a model that places boxes sloppily.
The labeling config gives the annotator a set of box labels to draw over the image:
<View>
<Image name="image" value="$image"/>
<RectangleLabels name="bbox" toName="image">
<Label value="Cattle" background="#C66A3D"/>
<Label value="Building" background="#1F5B3F"/>
<Label value="Vehicle" background="#E0A458"/>
</RectangleLabels>
</View>
torchmetrics computes mAP from predictions and targets, and reads the IoU threshold straight off so you can report it honestly:
# pip install torchmetrics
import torch
from torchmetrics.detection import MeanAveragePrecision
# Boxes here are [x_min, y_min, x_max, y_max]; convert from COCO's
# [x, y, w, h] with x_max = x + w, y_max = y + h before scoring.
preds = [{"boxes": torch.tensor([[340.0, 120.0, 425.0, 230.0]]),
"scores": torch.tensor([0.92]),
"labels": torch.tensor([1])}]
target = [{"boxes": torch.tensor([[342.0, 118.0, 427.0, 232.0]]),
"labels": torch.tensor([1])}]
metric = MeanAveragePrecision(iou_thresholds=[0.5, 0.75])
metric.update(preds, target)
result = metric.compute()
print(f"mAP@0.50: {result['map_50']:.3f}")
print(f"mAP@0.75: {result['map_75']:.3f}") # stricter: punishes loose boxes
The gap between the two thresholds is the useful read: a model that scores well at 0.50 but poorly at 0.75 is finding the right objects but boxing them loosely, which matters when the box itself carries the measurement, such as counting tightly packed livestock or delineating a field.
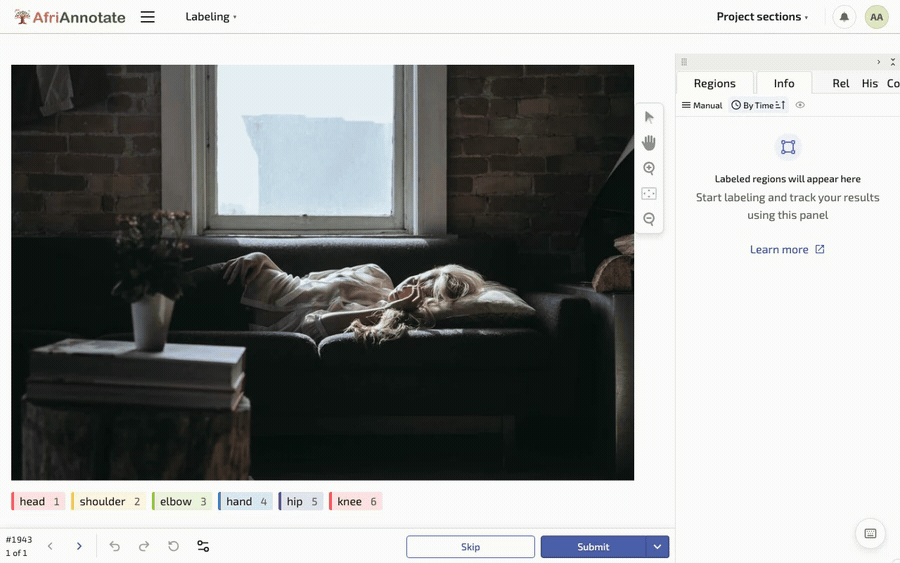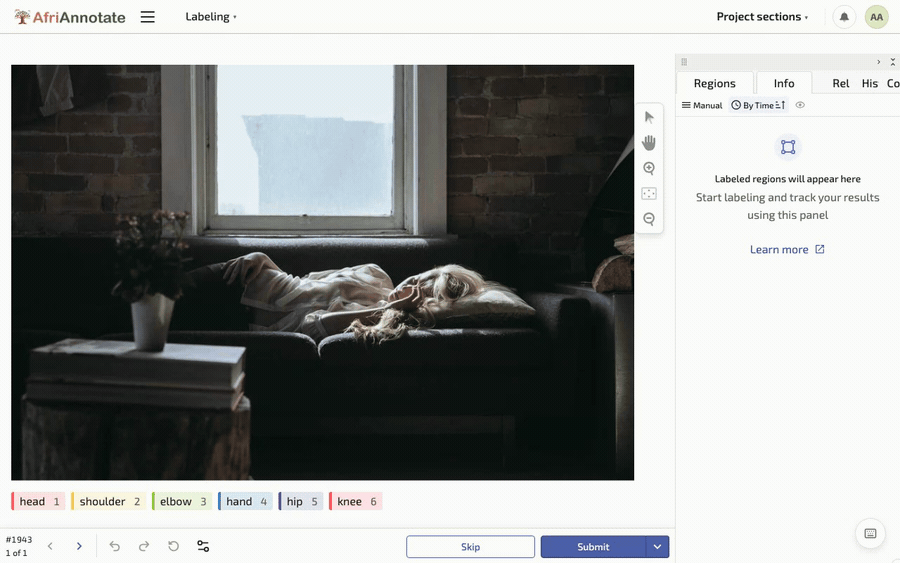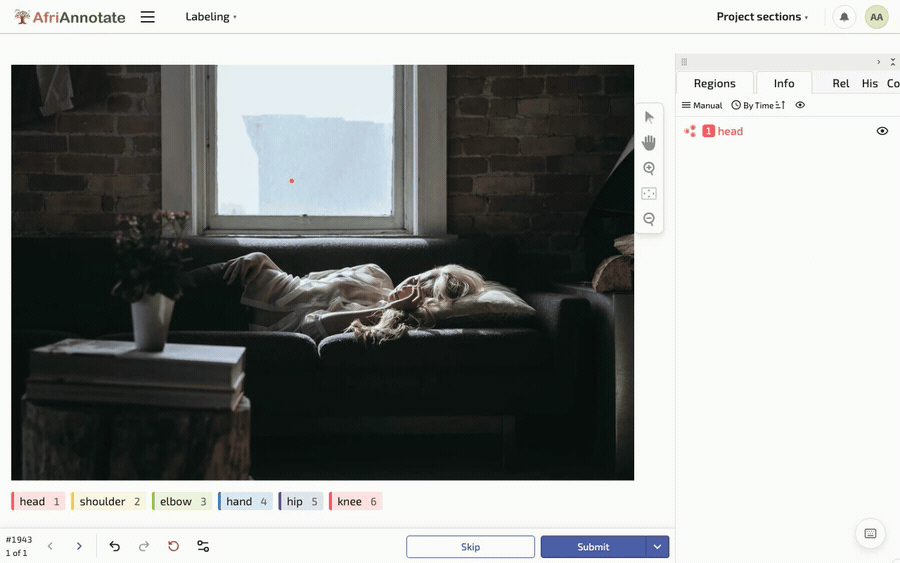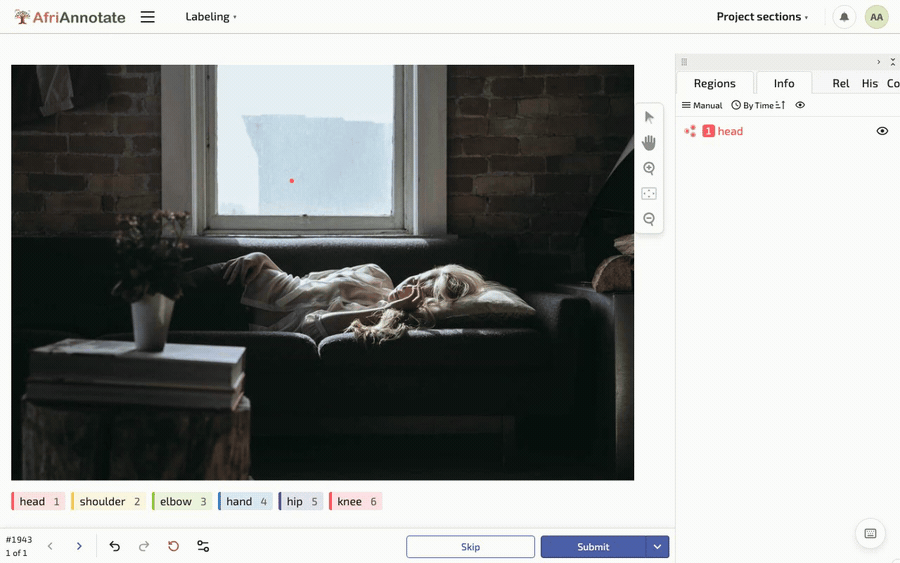
Drawing a box, and placing keypoints, in the AfriAnnotate editor: